
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- lruvec
- spinlock
- allocator
- page
- Linux
- pmap
- strex
- slowpath
- slab
- vm_area_struct
- vmalloc
- kmalloc
- BLOCK
- 카프카
- slub
- memory
- blk-mq
- mm_struct
- multiqueue
- Network
- fastpath
- devicedriver
- NDK
- Android
- kafka
- Apache
- proc
- Kernel
- commit
- buddy_system
- Today
- Total
Art of Pr0gr4m
[Linux Kernel 5] Block Device Driver Basic Concept 본문
블록 디바이스 드라이버는 Block 단위(사실은 세그먼트 단위)로 입출력을 하는 디바이스 드라이버다.
문자 디바이스 드라이버와의 가장 큰 차이는 Random Access 가능 여부다.
Random Access가 가능한 HDD, SSD 등을 제어하기 위해 사용한다.
단순히 데이터 스트림을 처리하는 문자 디바이스 드라이버와 다르게
제어해야할 범위도 넓고 성능 개선도 신경을 써야하기 때문에 기반에 깔린 개념들이 꽤나 복잡하다.
따라서 해당 포스트에서는 기반 개념들을 간단히 정리하고,
실제 디바이스 드라이버 예제는 다음 포스트에서 작성하기로 한다.
1. LBA
LBA는 Logical Block Addressing의 약자로 모든 블록을 선형적으로 다루는 모드이다.
참고로 섹터는 디스크상 저장 기본 Unit이고 블록은 파일시스템 상 저장 및 IO 기본 Unit 이다.
섹터의 크기는 전통적으로 512 Byte 였는데, 최근엔 2048 ~ 4096 Byte를 사용한다.
또한, Block은 일반적으로 하나 이상의 (n >= 1) 섹터를 가진다.
아무튼 과거 하드디스크의 경우엔 실린더 헤드 섹터라고 CHS 모드를 사용했는데
물리적 주소 지정을 튜플로 해야되는 번거로움이 있어 이를 선형적으로 표현한 것이 LBA라고 보면 이해가 쉽다.
그런데 이 LBA 모드는 플래터 윙윙 돌아가는 하드디스크를 타겟으로 한 호스트 인터페이스 모드이기 때문에
사실 SSD와의 근본적인 호환 문제가 생긴다 (덮어쓰기 관련)
그래서 이를 커버하기 위하여 SSD 컨트롤러는 FTL이라는 컴포넌트를 장착하고 있다.
이에 대해 더 자세한 내용은 다음 링크를 참고한다.
2. DMA
IO 작업을 하려면 당연히 CPU를 거쳐야 한다. IO 뿐 아니라 애시당초 명령은 CPU에서 처리한다.
주변 장치들이 서로 데이터를 주고 받는 과정에서 모든 데이터가 CPU를 거치도록 할 수 있다.
이를 PIO라고 한다.
그런데 IO 작업을 당연히 굉장히 느린 작업이다.
모든 데이터가 이렇게 CPU를 거치면 쓸데없는 오버헤드가 굉장히 심하다.
따라서 PIO의 단점을 보완하기 위해 DMA라는 개념이 고안되었다.
DMA는 시스템들이 CPU와 독립적으로 메인 메모리에 접근할 수 있게 해주는 기능이다.
이름 또한 Direct Memory Access의 약자이다. 이에 대해 자세한 내용은 링크를 참고한다.
위키피디아의 사진을 보면 그래픽카드와 SDI 카드가 DMA 기술을 통해서 통신을 하고있다.
이렇게 하위 시스템끼리의 데이터 교환뿐만 아니라,
디스크상의 데이터를 CPU를 거치지 않고 메인 메모리에 직접 전송하는 것도 가능하다.
물론, 정말 CPU에 아무런 신호를 주지 않고 제 멋대로 컨트롤러가 메모리에 접근하는 것은 아니다.
적어도 메인 메모리 공간 확보와 시스템 버스 소유권 획득 요청 및 처리 완료 통지는 CPU를 경유한다.
원래 DMA 전송은 한 번의 요청에 물리적으로 연속된 하나의 영역만 처리할 수 있었다.
현재는 이를 더 효율적으로 개선하여 물리적으로 연속되지 않은 여러 버퍼 대상으로
한번에 DMA를 전송할 수 있도록 scatter-gather DMA 방식을 사용한다.
사실 DMA에 대해 설명하자면 끝이 없기 때문에 이상 자세한 내용은 다음 링크를 참고한다.
3. struct buffer_head
struct buffer_head {
unsigned long b_state; /* buffer state bitmap (see above) */
struct buffer_head *b_this_page;/* circular list of page's buffers */
struct page *b_page; /* the page this bh is mapped to */
sector_t b_blocknr; /* start block number */
size_t b_size; /* size of mapping */
char *b_data; /* pointer to data within the page */
struct block_device *b_bdev;
bh_end_io_t *b_end_io; /* I/O completion */
void *b_private; /* reserved for b_end_io */
struct list_head b_assoc_buffers; /* associated with another mapping */
struct address_space *b_assoc_map; /* mapping this buffer is
associated with */
atomic_t b_count; /* users using this buffer_head */
};옛날 옛적 기본 IO 단위가 Block이었을 때, 단일 블록(single block)을 매핑하여 관리하기 위해
buffer_head를 사용했다. 그 때 당시에는 buffer_head 구조체의 내용이 굉장히 방대했다.
현재 IO 유닛은 블록을 여러개 모은 세그먼트이고 이는 bio로 관리된다.
그렇다고 buffer_head를 더 이상 사용하지 않는 것은 아니고,
매핑되어있는 블록을 세그먼트 내에서 추출할 때 사용한다.
(LBA에서 하드디스크 섹터는 전통적으로 512 바이트라고 했는데,
4K이상 큰 데이터를 처리할 때 4K 페이지에 512 바이트단위로 잘라서 처리하면 효율성은 당연히..)
4. struct bio
/*
* main unit of I/O for the block layer and lower layers (ie drivers and
* stacking drivers)
*/
struct bio {
struct bio *bi_next; /* request queue link */
struct gendisk *bi_disk;
unsigned int bi_opf; /* bottom bits req flags,
* top bits REQ_OP. Use
* accessors.
*/
unsigned short bi_flags; /* status, etc and bvec pool number */
unsigned short bi_ioprio;
unsigned short bi_write_hint;
blk_status_t bi_status;
u8 bi_partno;
atomic_t __bi_remaining;
struct bvec_iter bi_iter;
bio_end_io_t *bi_end_io;
void *bi_private;
#ifdef CONFIG_BLK_CGROUP
/*
* Represents the association of the css and request_queue for the bio.
* If a bio goes direct to device, it will not have a blkg as it will
* not have a request_queue associated with it. The reference is put
* on release of the bio.
*/
struct blkcg_gq *bi_blkg;
struct bio_issue bi_issue;
#ifdef CONFIG_BLK_CGROUP_IOCOST
u64 bi_iocost_cost;
#endif
#endif
union {
#if defined(CONFIG_BLK_DEV_INTEGRITY)
struct bio_integrity_payload *bi_integrity; /* data integrity */
#endif
};
unsigned short bi_vcnt; /* how many bio_vec's */
/*
* Everything starting with bi_max_vecs will be preserved by bio_reset()
*/
unsigned short bi_max_vecs; /* max bvl_vecs we can hold */
atomic_t __bi_cnt; /* pin count */
struct bio_vec *bi_io_vec; /* the actual vec list */
struct bio_set *bi_pool;
/*
* We can inline a number of vecs at the end of the bio, to avoid
* double allocations for a small number of bio_vecs. This member
* MUST obviously be kept at the very end of the bio.
*/
struct bio_vec bi_inline_vecs[0];
};
/*
* was unsigned short, but we might as well be ready for > 64kB I/O pages
*/
struct bio_vec {
struct page *bv_page;
unsigned int bv_len;
unsigned int bv_offset;
};bio 구조체는 여러 블록을 세그먼트로 묶어서 처리하는 구조체로 IO의 기본 유닛이다.
bio 구조체는 여러 개의 IO 요청을 처리하기 위하여 리스트로 관리된다.
또한, 실제 데이터 관리는 bio_vec 구조체 배열로 한다.
해당 배열은 여러개 블록이 모인 세그먼트를 나타낸다.
bio, bio_vec, page 상의 관계를 그림으로 나타내면 다음과 같다.

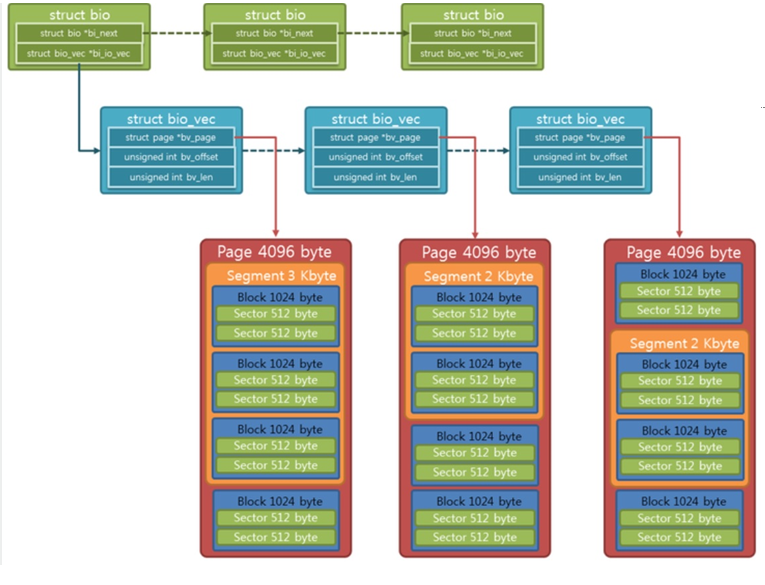
bio_vec 구조체는 메모리의 페이지를 나타내는 bv_page, 세그먼트 전체 길이를 나타내는 bv_len,
현재 작업중인 버퍼의 위치를 나타내는 bv_offset으로 구성된다.
커널은 물리 메모리를 페이지로 나눠서 page 구조체를 관리한다.
page 구조체는 dma 주소, slab 리스트, 메모리 매핑 private 데이터 등
다양한 방식으로 페이지를 나타내며 이를 union으로 묶는다.
5. IO Request와 IO 스케줄러
sg(scatter-gather) DMA 방식에서 여러 대상에 대해 한번에 DMA 전송을 처리할 수 있다고 하였다.
해당 개념에 맞게 커널은 IO 요청을 모아서 관리하여 DMA 전송을 처리한다.
이런 관리에는 여러 IO 요청을 묶음 처리하는 병합과 효율적인 순서 구성을 위한 정렬이 있다.
IO 스케줄러는 IO 요청들에 대해 merge와 sort를 수행하여 블록 디바이스 드라이버에게 요청을 보낸다.
아래 그림은 IO 시스템들을 계층화하여 나타낸다.
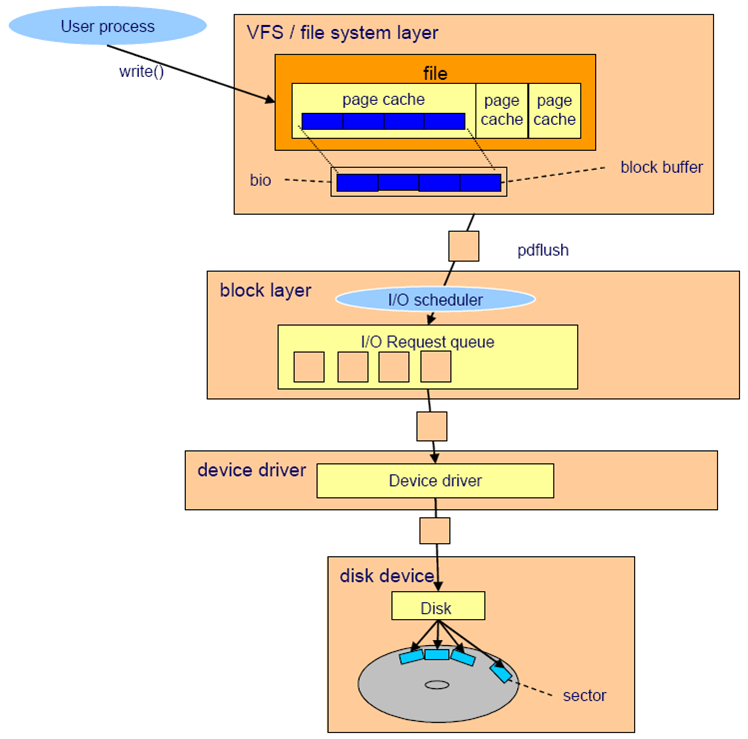
(사실 위 그림의 file system layer는 VFS, 실제 매핑 레이어, 제너릭 블록 레이어로 나눠 더욱 세분화해야 한다)
여기서 커널이 다루는 IO 요청은 request 구조체로 관리되며 이는 IO 스케줄러가 처리한다.
해당 구조체에서 특정 구현을 위한 데이터를 제외하면 다음과 같다.
/*
* Try to put the fields that are referenced together in the same cacheline.
*
* If you modify this structure, make sure to update blk_rq_init() and
* especially blk_mq_rq_ctx_init() to take care of the added fields.
*/
struct request {
struct request_queue *q;
struct blk_mq_ctx *mq_ctx;
struct blk_mq_hw_ctx *mq_hctx;
unsigned int cmd_flags; /* op and common flags */
req_flags_t rq_flags;
int tag;
int internal_tag;
/* the following two fields are internal, NEVER access directly */
unsigned int __data_len; /* total data len */
sector_t __sector; /* sector cursor */
struct bio *bio;
struct bio *biotail;
struct list_head queuelist;
struct gendisk *rq_disk;
/*
* Number of scatter-gather DMA addr+len pairs after
* physical address coalescing is performed.
*/
unsigned short nr_phys_segments;
#if defined(CONFIG_BLK_DEV_INTEGRITY)
unsigned short nr_integrity_segments;
#endif
unsigned short ioprio;
rq_end_io_fn *end_io;
void *end_io_data;
};request 구조체에는 bio 구조체에 접근하기 위한 멤버와,
IO 요청이 완료되었을때 호출할 함수를 지정할 end_io가 있다.
nr_phys_segments는 address coalscing을 수행한 후의 세그먼트 수를 나타낸다.
(= sg DMA addr + len pair의 숫자)
DMA address coalscing은 메모리 상 여러 블록을 버스 메모리 상 연속적인 하나의 블록으로 합친다.
물리적으로 근접한 장소에 위치한 요청들은 병합하여 한번에 처리하는 것이 효율적이다.
request_queue는 요청들을 관리하기 위한 큐이다.
6. IO 스케줄러의 종류
IO 스케줄러 자체를 공부하기 위한 포스트가 아니므로 (전부 설명하기엔 과거의 스케줄러부터
현대의 스케줄러까지 종류와 내용이 너무너무 방대하다) 링크로 대체한다.
http://wiki.linuxquestions.org/wiki/Elevator_linus
http://wiki.linuxquestions.org/wiki/Elevator_linus
wiki.linuxquestions.org
리누즈 엘레베이터는 병합의 기반이 되는 고전 스케줄러이다.
http://wiki.linuxquestions.org/wiki/Deadline
http://wiki.linuxquestions.org/wiki/Deadline
wiki.linuxquestions.org
데드라인 스케줄러는 Starvation 문제점을 해결하기 위한 고전 스케줄러이다.
http://wiki.linuxquestions.org/wiki/As
http://wiki.linuxquestions.org/wiki/As
wiki.linuxquestions.org
예측 스케줄러는 하드디스크상 요청 병합 효율 증진을 위한 고전 스케줄러이다.
http://wiki.linuxquestions.org/wiki/CFQ
http://wiki.linuxquestions.org/wiki/CFQ
wiki.linuxquestions.org
cfq는 프로세스 마다 request queue를 만들어 모든 프로세스가 우선순위(nice 값)에 따라 공평하게 IO 요청을 처리할 기회를 부여받는 고전 스케줄러이다.
https://www.kernel.org/doc/html/latest/block/bfq-iosched.html
BFQ (Budget Fair Queueing) — The Linux Kernel documentation
Low latency for interactive applications Regardless of the actual background workload, BFQ guarantees that, for interactive tasks, the storage device is virtually as responsive as if it was idle. For example, even if one or more of the following background
www.kernel.org
bfq는 태스크들에 time값 대신 budget 값을 부여하여 처리하는 현대 스케줄러로 cfq를 대체한다.
https://github.com/torvalds/linux/blob/master/block/mq-deadline.c
torvalds/linux
Linux kernel source tree. Contribute to torvalds/linux development by creating an account on GitHub.
github.com
mq-deadline은 기존의 deadline 스케줄러에 mq(MultiQueue)를 적용한 스케줄러로 deadline을 대체한다.
https://lwn.net/Articles/720675/
Two new block I/O schedulers for 4.12 [LWN.net]
Benefits for LWN subscribersThe primary benefit from subscribing to LWN is helping to keep us publishing, but, beyond that, subscribers get immediate access to all site content and access to a number of extra site features. Please sign up today! By Jonatha
lwn.net
kyber는 scascalable token based algorithm을 적용하여 mq를 사용하는 현대 스케줄러로 fast mq 디바이스에서 사용한다. (굉장히 복잡한 bfq에 비해 간결하다.)
http://wiki.linuxquestions.org/wiki/Noop
http://wiki.linuxquestions.org/wiki/Noop
wiki.linuxquestions.org
noop은 병합 작업만 진행하는 스케줄러이다.
모든 Random Access에 동일한 시간이 걸리는 플래시 메모리의 경우
1 -> 3 -> 5로 접근하나 1 -> 5 -> 3으로 접근하나 같은 시간이 소요된다면 sort가 필요없다.
이런 경우 sort 작업에 드는 시간을 없애기 위하여 사용한다.
이상 블록 디바이스 드라이버를 이해하기 위한 기반 개념들을 공부하였다.
다음 포스트에서는 이를 바탕으로 커널 5버전에서 동작하는 드라이버 예제를 작성한다.
'IT > Linux Kernel' 카테고리의 다른 글
| [Linux Kernel 5] Linked List (0) | 2020.05.10 |
|---|---|
| [Linux Kernel 5] Block Device Driver Example (0) | 2020.05.04 |
| [Linux Kernel 5] Kernel Timer (jiffies & ktime) (0) | 2020.05.02 |
| [Linux Kernel 5] proc & seq_file (0) | 2020.05.02 |
| [Linux Kernel 5] Crypto Device Driver (0) | 2020.04.30 |



