
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- BLOCK
- proc
- strex
- lruvec
- buddy_system
- Android
- Linux
- slowpath
- NDK
- slub
- slab
- allocator
- memory
- kmalloc
- spinlock
- fastpath
- vmalloc
- multiqueue
- Apache
- devicedriver
- mm_struct
- 카프카
- Kernel
- blk-mq
- Network
- kafka
- page
- pmap
- vm_area_struct
- commit
- Today
- Total
Art of Pr0gr4m
[번역] Kafka 시작하기 #1 본문
해당 글은 https://kafka.apache.org/documentation/ 문서를 번역하고 있습니다.
개인 공부의 비중이 크기 때문에, 직역보다는 의역이 많을 수 있으며, 필자의 주석 등이 있을 수 있습니다.
-----
1.1 소개
아파치 카프카는 분산 스트리밍 플랫폼입니다. 그것이 무엇을 의미하는지 알아보겠습니다.
스트리밍 플랫폼은 세 가지 주요 기능이 있습니다:
- 레코드 스트림을 Publish/Subscribe 하는 기능이 있습니다. 이는 메세지 큐나 엔터프라이즈 메세징 시스템과 비슷합니다. (Publish/Subscribe를 모르신다면, Publish는 데이터를 생성하고 Subscribe는 해당 데이터를 읽어 소비하는 걸로 우선 알고 있으시면 충분합니다.)
- 결함 감내(fault-tolerant)가 우수한 방법으로 레코드 스트림을 저장합니다.
- 레코드 스트림이 발생하면 처리(Process)합니다.
카프카는 일반적으로 두 가지 큰 범위의 애플리케이션에 사용합니다.
- 시스템이나 애플리케이션간 데이터를 안정적으로 얻기 위한 리얼 타임 스트리밍 데이터 파이프라인을 구축합니다.
- 데이터 스트림을 변환하거나 반응(react)하는 리얼 타임 스트리밍 애플리케이션을 구축합니다.
카프카가 이러한 것들을 어떻게 수행하는지 이해하기 위하여, 카프카의 기능을 bottom up 방식으로 탐구해 봅시다.
먼저 몇 가지 기본 개념이 있습니다.
- 카프카는 여러 데이터센터로 확장할 수 있는 하나 혹은 그 이상의 서버에서 클러스터로 실행(수행/운영) 됩니다.
- 카프카 클러스터는 레코드(records)라는 스트림을 토픽(topics)이라고 불리는 카테고리에 저장합니다.
- 각각의 레코드는 키(a key,), 값(a value), 타임스탬프(a timestamp)로 구성됩니다.
카프카는 네 가지 주요한(core) API를 제공합니다.

- 프로듀서(Producer) API는 애플리케이션이 레코드 스트림을 하나 이상의 토픽에 Publish 할 수 있게 해줍니다.
- 컨슈머(Consumer) API는 애플리케이션이 하나 이상의 토픽에서 레코드 스트림을 Subscribe 하고, 생성한 레코드를 처리할 수 있게 해줍니다.
- 스트림즈(Streams) API는 애플리케이션이 스트림 처리기(stream processor) 역할을 수행하게 해줍니다. 이는 하나 이상의 토픽에서 입력 스트림을 소비하고 하나 이상의 결과 토픽에 출력 스트림을 생성하여, 효과적으로 입력 스트림을 출력 스트림으로 변환 할 수 있습니다.
- 커넥터(Connector) API는 카프카 토픽을 기존에 존재하던 애플리케이션이나 데이터 시스템에 연결하는 재사용 가능한(reusable) 프로듀서나 컨슈머를 구축하거나 운영할 수 있게 해줍니다. 예를 들어, 관계형 데이터베이스에 대한 커넥터는 모든 테이블의 변화를 캡처할 수 있습니다.
카프카에서 클라이언트와 서버 간의 통신은 단순하고 고성능으로 언어 독립적인 TCP 프로토콜로 수행됩니다. 이 프로토콜은 버전이 지정되어 있으며, 하위 버전 호환성을 유지합니다. 또한 카프카를 위한 자바 클라이언트를 제공하는데, 클라이언트는 다양한 언어로 만들어질 수 있습니다.
토픽과 로그
토픽이라는 카프카가 제공하는 레코드 스트림을 위한 첫 번째 핵심 추상 기능에 대해 알아봅시다.
토픽은 레코드가 publish되는 카테고리 또는 피드의 이름입니다. 카프카에서 토픽은 항상 여러 subscriber를 가질 수 있습니다(multi-subscriber). 즉, 토픽은 기록된 데이터를 subscribe할 컨슈머를 여러 개(0개 이상) 가질 수 있습니다.
각각의 토픽에 대해, 카프카 클러스터는 다음과 같은 파티션된 로그를 유지합니다:
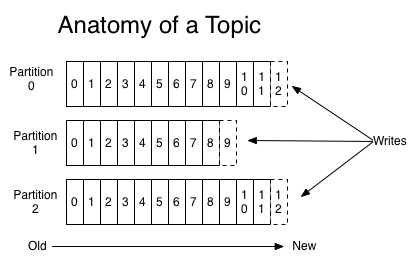
각각의 파티션은 연속적으로 추가되는 정렬되고 변하지않는 레코드의 순서이며, 이는 구조화된 커밋 로그입니다. 파티션에 있는 레코드들은 각자 파티션 내에서의 유일한 식별자 id 번호를 부여받는데, 이를 오프셋이라고 합니다.
카프카 클러스터는 모든 publish된 레코드들을 사용 여부와 관계 없이 보유 기간 설정에 따라 유지합니다. 예를 들어, 보유 기간이 이틀이라면면 레코드가 publish된 이 후 이틀간은 계속 사용할 수 있으며, 그 이후에는 가용 공간을 늘리기 위하여 제거됩니다. 카프카의 성능은 데이터의 크기와 관계 없이 일정하므로 데이터를 오랜 기간 저장 하는 것이 성능상 문제가 되지는 않습니다.

실제로 컨슈머 당 유지되는 유일한 메타데이터는 로그에서의 오프셋 뿐입니다. 이 오프셋은 컨슈머가 제어합니다: 일반적으로 컨슈머의 오프셋은 레코드를 읽을 때마다 선형적으로 증가하지만, 오프셋의 위치를 컨슈머가 제어하므로 레코드를 원하는 순서로 소비할 수 있습니다. 예를 들어, 컨슈머가 과거의 데이터를 재처리하기 위하여 이 전 오프셋으로 리셋하거나, 가장 최근 레코드로 건너 뛰어 최신 레코드를 소비할 수 있습니다.
이러한 기능의 결합은 카프카 컨슈머의 사용으로 인한 비용이 적다는 것을 의미합니다(기능적 소요가 적다는 것을 의미합니다). 컨슈머는 클러스터나 다른 컨슈머에 영향을 거의 미치지 않고 사용할 수 있습니다. 예를 들어, 카프카에서 제공하는 커맨드 라인 툴을 이용하여 토픽의 내용을 기존 컨슈머에 영향을 주지 않고 꼬리 읽기(tail) 할 수 있습니다.
로그의 파티션은 다양한 용도로 사용됩니다. 먼저, 파티션은 로그의 크기를 단일 서버의 사이즈 이상으로 확장할 수 있게 해줍니다. 각각의 파티션은 각자가 호스트(host)하는 서버에 적합해 있으나, 토픽은 여러 파티션을 가질 수 있기에 임의의(arbitrary) 양의 데이터를 처리할 수 있습니다. 그리고, 그들은 병렬 처리 단위 처럼 동작합니다.
'IT > Kafka' 카테고리의 다른 글
| [실습] Kafka 설치하기 (1) | 2018.07.28 |
|---|
